Take control of your learning data with our Learning Record Store
An enterprise-ready LRS that’s right-sized for your business
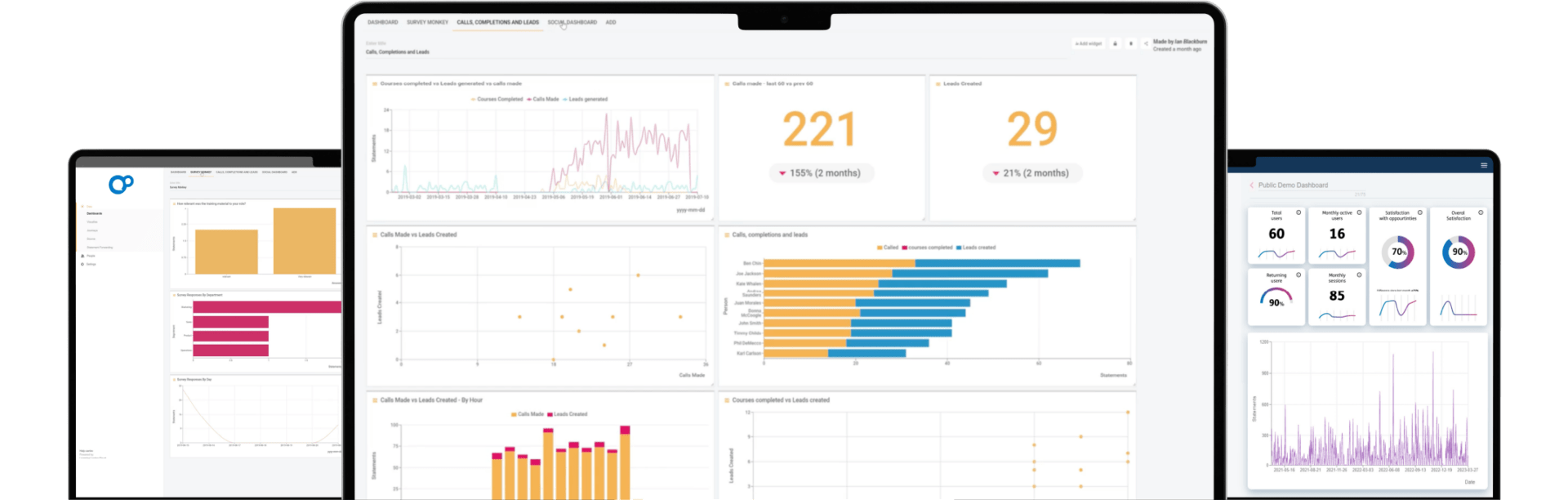
Combine and standardize multiple sources of data
Modern learning requires the use of data from multiple sources. But integrating this data can be expensive, time-consuming, and difficult to maintain. Our Learning Record Store (LRS) brings all of your learning data into a single space. Through the xAPI standard, it also captures and logs all learner activity, enabling greater insight.
What can you do with a Learning Record Store?
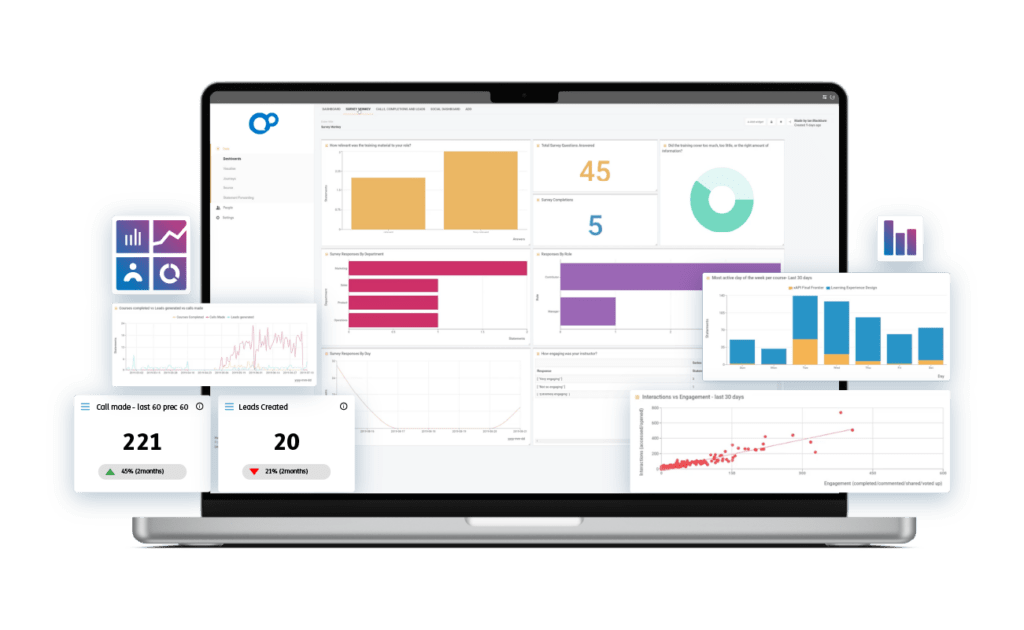
Aggregate
Scale massively, query on-demand, and create complex business rules to transform incoming data into new activity records.
Automate
Lean on granular, activity level data to automate administrative tasks.
Strategize
Integrate learning data with Business Intelligence (BI) tools for a more complete view of the impact of learning on business outcomes.
The world’s most installed Learning Record Store
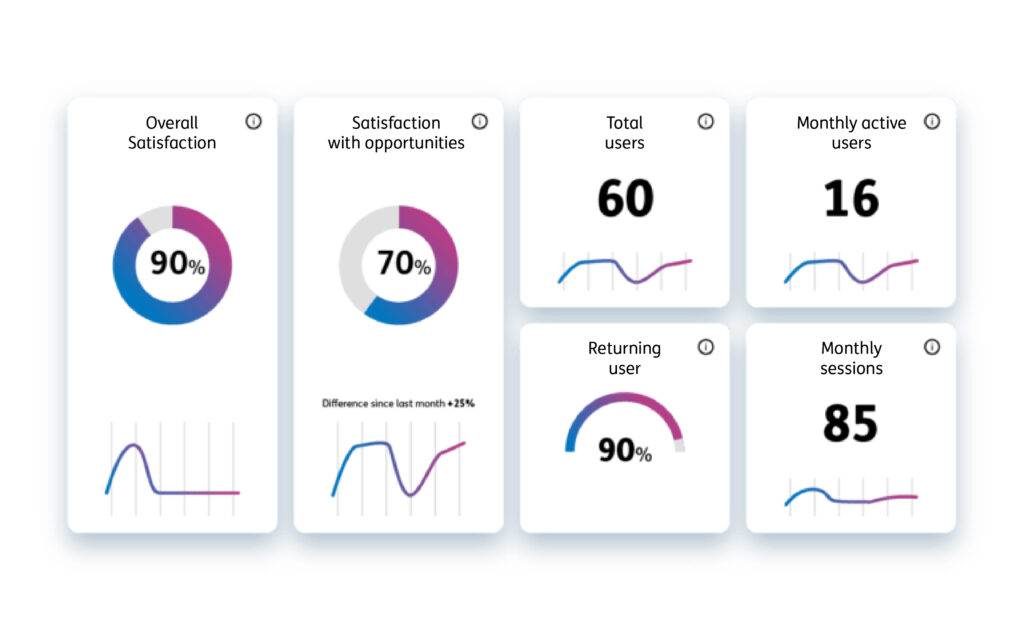
Fast, reliable, secure
Our LRS is ready to deliver at a scale global businesses demand. The modern UI ensures that your learning data is more accessible and useful than ever before.
xAPI compliant
Take multiple sources of learning data such as learning platform data, content data or survey data and quickly validate and combine them.
Supported
Dedicated technical support includes implementation support, online training, telephone support, and a hypercare phase to set you up for success.
A history of innovation

Our Learning Record Store began as an open source download (Learning Locker). In 2019, Learning Locker was awarded a Queen’s Award for Enterprise recognizing outstanding achievement in innovation.
The open source download is still available to individuals and developers who want to test the power and flexibility of xAPI-based data management for themselves.
Secure hosting and data privacy

ISO 27001 certified
We’re committed to protecting your data, meeting the requirements of good information security practice, and finding ways to improve our security to mitigate new risks. We utilize state of the art cloud hosting powered by Amazon Web Services (AWS,) who continually manage risk and undergo recurring assessments to ensure compliance with industry data center standards. We also conduct regular. independent third-party audits of our own management and data systems, all user passwords are encrypted, and we carry out annual penetration and vulnerability testing.
Frequently Asked Questions
What is a Learning Record Store (LRS)?
A Learning Record Store (LRS) is a system that stores and manages learning-related data, including records of learners’ activities, achievements, and experiences. It’s a key component of the xAPI (Experience API) ecosystem, designed to collect, store, and retrieve learning data from various sources.
How does a Learning Record Store work?
An LRS collects and stores data generated by learners’ interactions with various learning experiences, such as online courses, simulations, assessments, and more. This data is typically in the form of xAPI statements, which are structured records of learning activities. LRSs can then analyze and present this data to provide insights into learners’ progress and performance.
Why is an LRS important for organizations?
An LRS is crucial for organizations as it enables them to track, analyze, and improve their employees’ learning experiences. It helps in evaluating the effectiveness of training programs, identifying gaps, and making data-driven decisions to enhance training initiatives.
Excellence in learning data
Get in touch to discover how we can help
